Retrieval Augmented Generation (RAG): The Complete Enterprise Guide
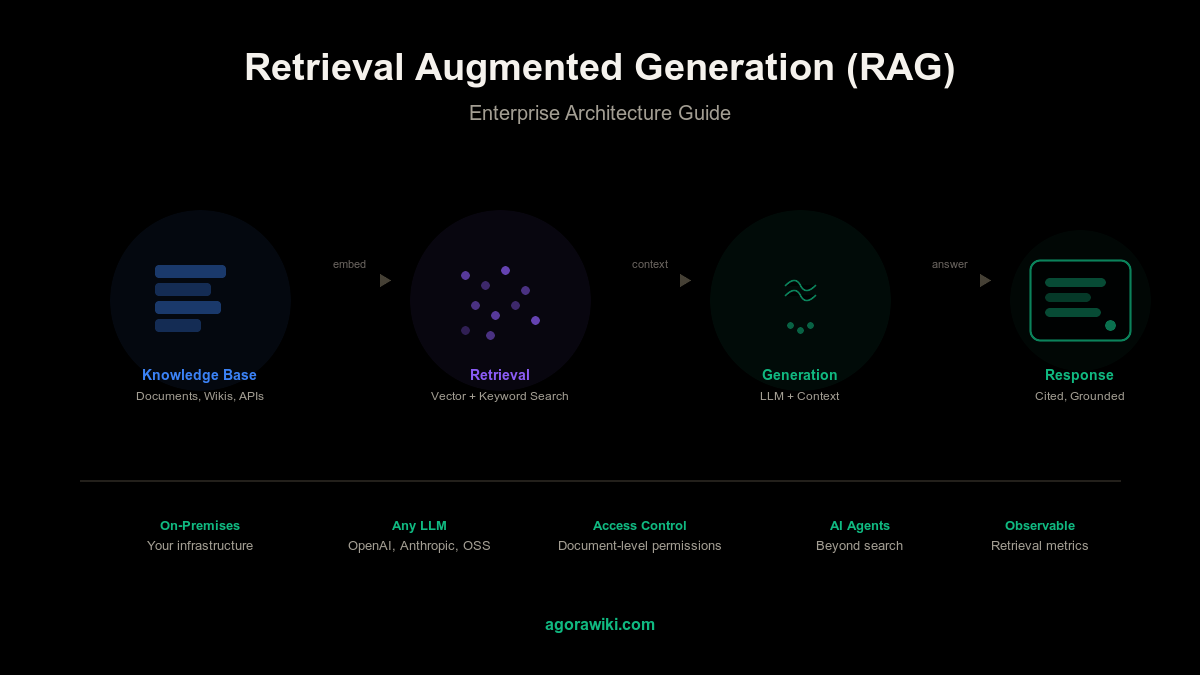
What Is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation - commonly known as RAG - is an AI architecture that combines information retrieval with large language model (LLM) text generation. Instead of relying solely on what a model learned during training, RAG systems first retrieve relevant documents from a knowledge base, then feed that context to the LLM to generate grounded, accurate responses.
The concept was introduced by Meta AI researchers in 2020, but it has since become the dominant pattern for building enterprise AI applications that need to answer questions about proprietary data - company wikis, internal documents, support tickets, product specifications, and more.
In simple terms: RAG gives an LLM the ability to “look things up” before answering, similar to how a person might search their company’s knowledge base before responding to a colleague’s question.
How Does Retrieval Augmented Generation Work?
A RAG system operates in three stages:
1. Indexing (offline)
Documents are broken into chunks, converted into numerical representations (embeddings) via an embedding model, and stored in a vector database. This preprocessing step turns unstructured content into a searchable format optimized for semantic similarity.
2. Retrieval (at query time)
When a user asks a question, the system converts that query into an embedding and searches the vector database for the most semantically similar document chunks. Advanced RAG systems combine this with keyword search (hybrid retrieval) for higher recall.
3. Generation (at query time)
The retrieved document chunks are injected into the LLM’s prompt as context. The model then generates a response grounded in the retrieved information rather than relying purely on its parametric knowledge.
This three-stage pipeline is what separates RAG from vanilla LLM usage. The retrieval step acts as a grounding mechanism - reducing hallucinations and ensuring responses reflect current, organization-specific information rather than outdated training data.
Why Enterprise RAG Is Different from Basic RAG
A proof-of-concept RAG system - load some PDFs, chunk them, embed them, query with an LLM - can be built in an afternoon. Enterprise RAG is a fundamentally different challenge.
Scale and complexity
Enterprise environments deal with millions of documents across dozens of systems: Confluence, SharePoint, Google Drive, Slack, Jira, Notion, internal databases, email archives. An enterprise RAG solution must ingest from all of these, handle incremental updates, resolve conflicting versions, and maintain freshness as source documents change.
Access control
Not every employee should see every document. Enterprise RAG must enforce document-level and even paragraph-level permissions, ensuring the LLM never surfaces information a user isn’t authorized to access. This requires deep integration with identity providers and the permission models of each connected data source.
Accuracy at stakes
When an engineer asks a consumer chatbot a question and gets an approximate answer, the cost of error is low. When a compliance officer queries an enterprise RAG system about regulatory requirements, or when a support agent uses it to guide a customer through a safety procedure, hallucinations become a liability. Enterprise RAG demands citation, confidence scoring, and transparent source attribution.
Deployment constraints
Many organizations - in defense, healthcare, finance, and government - cannot send proprietary data to third-party cloud APIs. Enterprise RAG must support on-premises deployment, air-gapped environments, and data residency requirements.
Enterprise RAG Architecture: Key Components
A production-grade enterprise RAG system consists of several interconnected layers:
| Component | Purpose | Enterprise considerations |
|---|---|---|
| Data connectors | Ingest from source systems | Must support 20+ integrations, incremental sync, access control inheritance |
| Document processing | Chunking, cleaning, metadata extraction | Table handling, OCR for scans, multi-language support |
| Embedding model | Convert text to vector representations | On-prem model hosting, domain-specific fine-tuning |
| Vector database | Store and search embeddings | Horizontal scaling, multi-tenancy, backup/recovery |
| Retrieval engine | Hybrid search (vector + keyword) | Re-ranking, query expansion, filtering by metadata/permissions |
| LLM layer | Generate responses from context | Model flexibility, self-hosted options, cost management |
| Agent layer | Multi-step reasoning, tool use | Workflow automation, human-in-the-loop, audit trails |
| Observability | Monitor quality and usage | Retrieval relevance metrics, hallucination detection, usage analytics |
RAG vs Fine-Tuning: When to Use Which
A common question in enterprise AI strategy is whether to use RAG or fine-tune a model on proprietary data. They solve different problems:
Use RAG when:
- Your knowledge changes frequently (documents updated daily/weekly)
- You need source attribution and citations
- Users query across a broad knowledge base
- You need to enforce access controls on retrieved content
- Freshness matters - you can’t afford retraining cycles
Use fine-tuning when:
- You need the model to adopt a consistent style or domain vocabulary
- The knowledge is relatively static and universal across users
- You want to improve task performance on a specific pattern
- Response latency is critical (retrieval adds time)
In practice, enterprise deployments often combine both: a fine-tuned model that understands domain terminology, enhanced by RAG for current, document-grounded answers. This hybrid approach delivers both fluency and accuracy.
How to Evaluate an Enterprise RAG Platform
Not all RAG solutions are equal. When evaluating platforms for enterprise deployment, these dimensions matter most:
Data source coverage
How many systems can it connect to natively? What happens when you need a connector that doesn’t exist? The best platforms provide both pre-built connectors and an extensible framework for custom integrations.
Retrieval quality
Does it support hybrid search (vector + BM25)? Can it re-rank results? Does it handle multi-hop queries where the answer spans multiple documents? Ask vendors for retrieval benchmarks on enterprise-style questions - not just academic datasets.
LLM flexibility
Are you locked into a single model provider, or can you bring your own? Enterprise requirements shift: you may start with OpenAI, move to Anthropic, or deploy open-source models like Llama for cost or compliance reasons. Platform lock-in here is expensive.
Deployment model
Can it run on your infrastructure? True on-premises (bare metal, your data center) is different from “customer-hosted cloud” (still requires internet connectivity). For regulated industries, air-gapped deployment is non-negotiable.
Security and governance
How does it handle permissions? Is there audit logging? Can administrators control which documents feed which user groups? Does it support SSO, RBAC, and multi-tenancy?
Observability and iteration
Can you measure retrieval relevance? Track which queries succeed or fail? Identify knowledge gaps? A RAG system without observability is a black box you can’t improve.
Building vs. Buying Enterprise RAG
Organizations face a fundamental build-or-buy decision with RAG:
Building from scratch using frameworks like LangChain, LlamaIndex, or Haystack gives maximum flexibility but requires significant engineering investment. You own the infrastructure, the chunking strategy, the retrieval pipeline, and the prompt engineering. Teams typically spend 6-12 months reaching production quality, and ongoing maintenance is substantial.
Buying a platform trades customization for speed-to-value. The right platform handles the undifferentiated heavy lifting - connectors, document processing, vector storage, access control - while letting your team focus on the use cases that matter.
The key question is whether RAG infrastructure is your core differentiator. For most organizations, it isn’t - the value is in the knowledge itself and the workflows built on top. In those cases, a platform that handles the RAG infrastructure while giving you control over deployment, models, and data is the pragmatic choice.
Enterprise RAG with Agora
Agora is a complete enterprise RAG platform designed for organizations that need production-grade AI search and agents without sacrificing control over their data or infrastructure.
Full deployment flexibility - Deploy via Docker Compose for quick evaluation or Kubernetes/Helm for production. Run on your hardware, your cloud, or air-gapped. Your data never leaves your perimeter.
Connector ecosystem - Pre-built integrations with Confluence, SharePoint, Google Drive, Slack, Notion, Jira, and more. Custom connectors via Python SDK for proprietary systems.
Model independence - Bring any LLM: OpenAI, Anthropic, Google, or self-hosted open-source models. Swap providers without re-architecting. Same flexibility for embedding models and vector databases.
Enterprise security - Document-level access control inherited from source systems. SSO, RBAC, multi-tenancy, and complete audit logging.
Beyond retrieval - Agora includes an AI agent layer for multi-step workflows, autonomous task execution, and proactive knowledge delivery - not just question-answering.
# Get started in minutes
docker compose up -dFrequently Asked Questions
What is Retrieval Augmented Generation in simple terms?
RAG is a technique where an AI system searches a knowledge base for relevant information before generating a response. Think of it as giving an LLM a research assistant - instead of answering from memory alone, it looks up current, specific information first.
Is Retrieval Augmented Generation the same as fine-tuning?
No. Fine-tuning permanently changes a model’s weights by training on new data. RAG keeps the model unchanged but provides relevant documents at query time. RAG is better for dynamic knowledge that changes frequently; fine-tuning is better for encoding style or static domain patterns.
How much does enterprise RAG cost?
Costs vary significantly by deployment model. Cloud-hosted RAG platforms like Glean typically start at $10-15 per user per month with minimum seat counts. Self-hosted platforms like Agora have infrastructure costs (compute, storage) but no per-seat licensing, making them more economical at scale - especially above 500 users.
Can RAG be deployed on-premises?
Some platforms support it, many don’t. Cloud-only solutions (Glean, Guru) cannot run on your hardware. Open-source options (Onyx) support self-hosting but often lack enterprise features in their free tier. Agora supports full on-premises deployment including air-gapped environments with no internet dependency.
Related Reading
- The Hidden Cost of Disorganization: How Fragmented Documentation Drains Productivity
- Large Language Models (LLM) - The Brains Behind Smarter and Faster Work
- Agora vs Glean: Enterprise AI Search Platform Comparison
- Agora vs Onyx: Open Enterprise AI Platforms Compared
Ready to deploy enterprise RAG on your own infrastructure? Book a demo or try the admin console to see Agora’s RAG platform in action.